

A commonly held belief is that web scraping allows you to instantly extract anything from the web. But, in reality, web scraping comes with significant limitations. These can stem from changing website structures, varying data formats, and legal restrictions, to name a few.
This blog post explains what web scraping can do at its best, and why alternative approaches, including manual data extraction, can often be the more efficient solution.
Web Scraping- a Magical Cure to all Data Sourcing?
Web scraping is often imagined as a data vending machine- insert a link to a website and receive your bounty of selected data, ready to be manipulated and analysed to your heart's content. This is often done using packages like BeautifulSoup and Selenium. Web scraping is usually performed in two steps:
Downloading and parsing the data.
Selecting which data to extract, in what format, and which elements to ignore. This forms the “instructions” built into your code.
This is why web scraping works extremely well on highly structured data sources, such as Wikipedia or BBC news. These websites have very repetitive, predictable formats, which means the instructions on what to extract are easy to write and adapt, even across different pages.
In a matter of seconds, you can download huge amounts of data- and the best part is that you can be extremely selective over which bits of data you want.

With a well structured input and specific instructions on what data to pull out, web scraping can be effective at extracting data quickly. Instructions may look something like this: “Select columns 1, 5, & 7 as floats from the third table on the website.”
However, if you’re looking to aggregate data from several websites, you’re going to run into a problem. This is the crux of the problem of web scraping at scale…
Location, Location, Location
Let’s imagine you’re looking to aggregate a list of movie ratings by web scraping several film ranking websites.
Every website has its own flair. And for each new website your web scraping code needs to be carefully tuned to know where to find the data and what format to extract. For example, IMDb might host movie rankings as a table, Letterboxd might use a list written in plain English, and a popular blog might use embedded PDFs.
Each website will need bespoke instructions on where and how to find the data. Even if, by some miracle, all the websites publish their rankings in neatly structured tables, you still need to specify where to find each table on every website. And there’s no guarantee they’ll be in the same location. You get the picture.
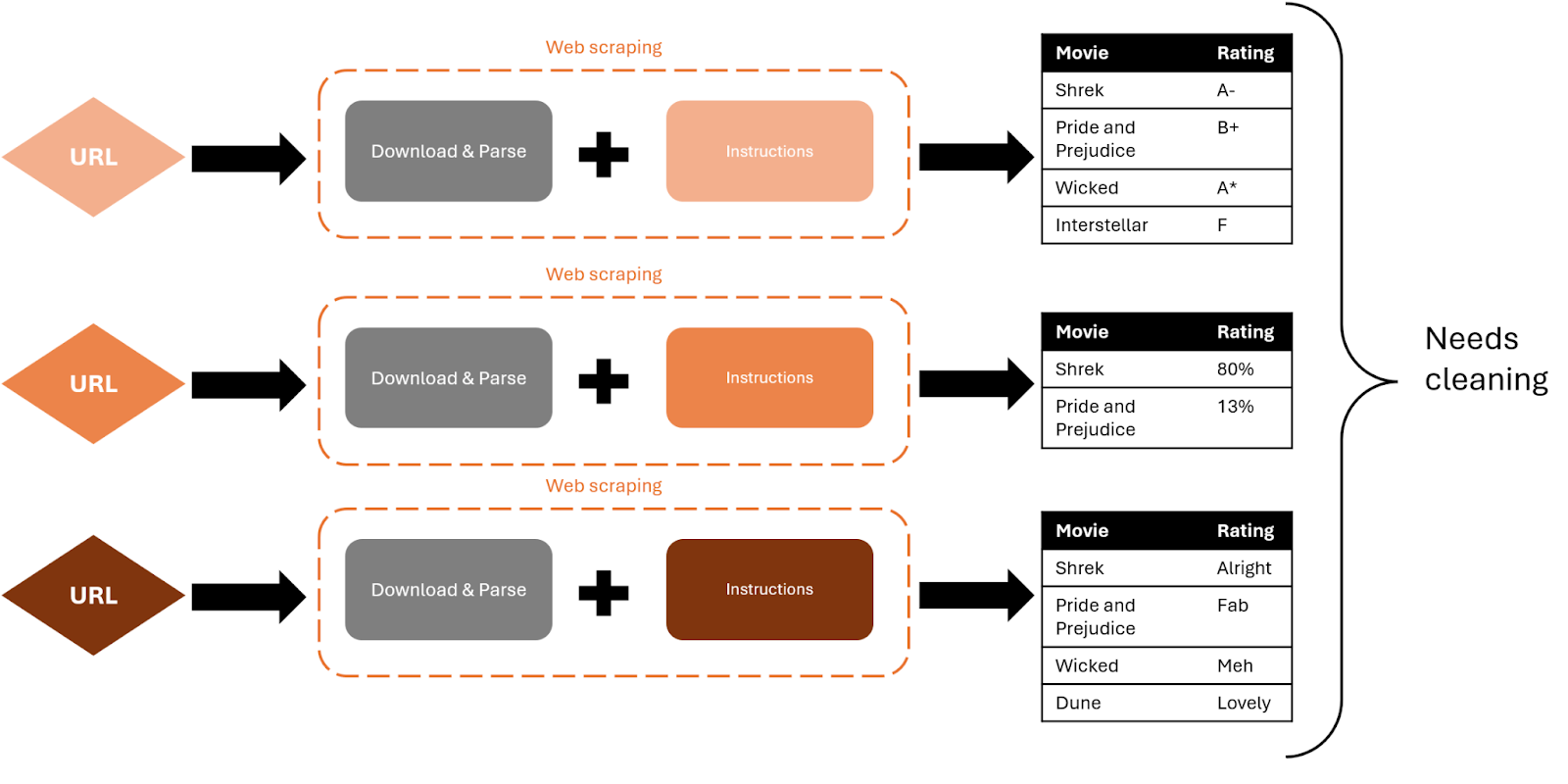
New instructions have to be written for each new website, which can be tedious. The aggregated data will also need a lot of cleaning due to different data types.
And this doesn’t even account for the manual labour of tracking down the unique URLs where the data is stored. For data hosted on hundreds of different websites, this is no trivial task.
In addition to this, each website might have their own way of recording data. Is it in units of 10s, 100s, 1000s? What about special cases? Are they recording data as text or values? With each additional data source, you now need to think about cleaning each dataset to get a cohesive and accurate aggregated dataset.
Woop Woop, That’s the Sound of the Police
A final challenge is legal. Although web scraping is not technically illegal, there are extensive protections around what can and can’t be web scraped- ranging from database infringement to breach of copyright.
Each website hides its policies within its T&Cs, and there’s no way to know whether they consider web scraping fair use without digging through pages of legal jargon for each URL - taking up precious time.
To Scrape or Not To Scrape?
We’ve seen that web scraping can have a huge number of associated problems. These challenges are usually technical or legal and can make web scraping take longer than manual collection.
So is it worth web scraping? Absolutely- if applied to the appropriate problem.
If your data passes these tests, then web scraping very well may save you hours of mindless copy-pasting data:
Do you know specifically where to find all your data?
Is that data similarly structured and formatted at all data sources?
Do you have the relevant permissions to web scrape?
Wrapping up
Web scraping can present logistical, technical, and legal challenges. That’s why it’s important to anticipate these challenges before starting and seriously assess whether web scraping will actually save you time. Data cleaning can make or break the entire process, and in many cases, it’s better to knuckle down for a few hours and just collect the data yourself by visiting each website and copy-pasting the data by hand, manually cleaning as you go.
Make sure to always check the T&Cs behind the data, and take a look at alternative methods of data collection, such as structured APIs, which might be better suited for different problems.
This blog post covered:
The power of web scraping.
Why data structure and location are critical.
The challenges of web scraping - technical, legal, and logistical.
Want to know how to start web scraping? Head to my GitHub demo- which is closely based on this excellent YouTube video by AlexTheAnalyst which explains the process.